Read the English version published on May 20, 2022.
世界各国の政府、市民、企業は温室効果ガス(GHG)排出量の削減に向けた取り組みをますます活発化させています。投資家にとって、ポートフォリオ企業のGHG排出量をモニタリングすることは投資プロセスにおける重要な側面となりつつあります。しかし、取得できるGHG排出量報告データは国や業種によって量や質が大幅に異なり、排出量を一切開示していない企業も多数あります。
このデータ格差を補完するため、ブルームバーグは各企業のGHG排出量を推定する機械学習ベースのモデルを開発しました。ブルームバーグGHGモデルを使用すると、企業の直接的(スコープ1)および間接的(スコープ2、3)排出量を十分なデータを用いて推定できます。
2010-2020年の炭素排出量報告データ
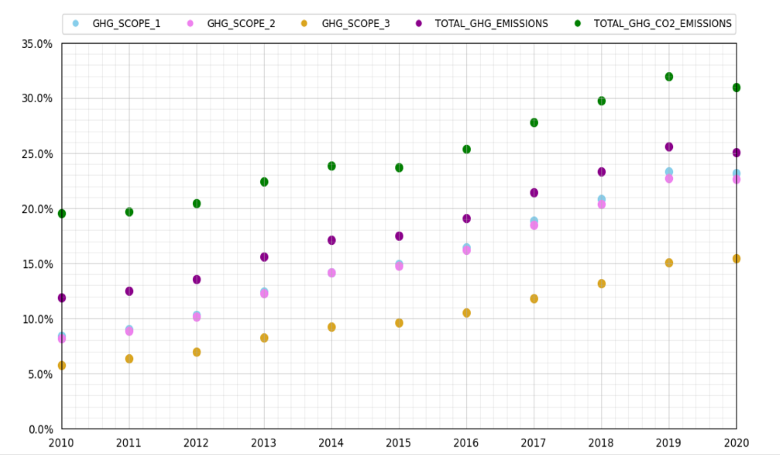
図1:ブルームバーグESGユニバース(現在1万1900社で構成)に属するESGデータを開示している企業のうち、各GHG排出量データを報告している企業の割合
スコープ1および2モデルの対象となる企業とは?
当モデルでは2010年以降、世界で合計5万社以上の企業を網羅してきました。そのうち、3万9000社は上場企業、1万1000社は非上場企業です。以下の各表は、指数別、地域別、国別の内訳を示しています。
インデックス別-スコープ1および2対象企業
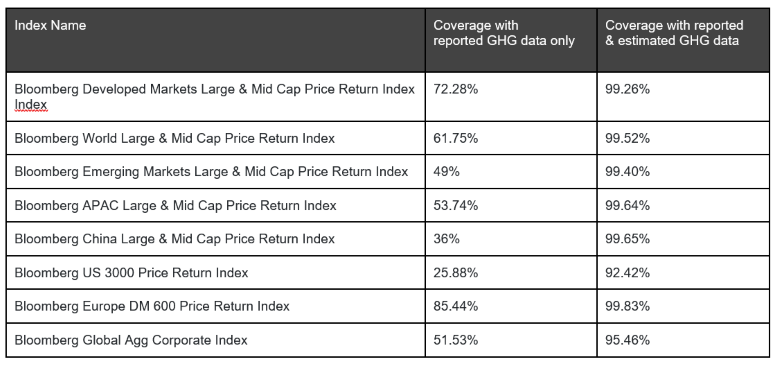
表1:指数別-スコープ1および2対象企業
スコープ3モデルの対象企業とは?
スコープ3GHG排出量推定は世界各国の4,000社超を網羅しています。そのうち、約90%が上場企業、残りは非上場企業です。
インデックス別-スコープ3対象企業

表4:指数別-スコープ3対象企業数
GHG排出量推定における最適モデルの決定方法
各企業の二酸化炭素排出量の推定はそれ自体が複雑な作業です。さらに、推定に必要な企業のデータにノイズや不備がある場合もあります。通常は線形モデルを使用すれば説明可能性が高くなるものの、原データに相互依存性、欠損値、および(数値データではなく)カテゴリーデータ―すなわちGHG推定値算出の妨げとなる諸問題―がある場合は、適切に機能しません。一方で、回帰木分析のような複雑な機械学習モデルを使用すれば、データに含まれる複雑な関係性を自ずと学習し、欠損値に対応し、カテゴリーデータを処理した上で、GHG排出量に内在するノイズをモデル化することができます。
モデルが参照するデータ
GHG排出量推定の質は、値の算出に使われるデータの質に大きく左右されますが、これこそブルームバーグの強みが発揮される分野です。ブルームバーグGHGモデルではあらゆるデータセットが使用されます。例えば、企業の拠点、規模、財務情報、環境・社会・ガバナンス(ESG)データ、セクターごとの収益内訳、そして業種特有の企業データが挙げられます。業種特有データとは、公益事業が発電に使用するエネルギー源(化石燃料、太陽光、風力など)のほか、セメント会社、鉄鋼会社、石油・ガス会社の生産データなどを指します。本モデルでは合計で800種類以上のデータが活用されます。
モデルの出力データ
ブルームバーグGHGモデルはスコア1および2については全セクター、スコープ3については石油・ガスおよび鉱業セクターを対象に推定値を算出します。各推定値には比較対象企業群との比較に基づく独自の分布が表示されます。これにより、ユーザーはその分布内のさまざまなパーセンタイルを選択して、分布の平均値という1つだけの選択肢ではなく、積極的な推定値や保守的な推定値も活用できます。
ブルームバーグソリューションのもう1つの要素は「GHG信頼スコア」です。これは特定の企業のGHG排出量予想算出に利用可能なデータポイントのと関連度を測定するものです。GHG信頼スコアは、任意の企業について取得できるデータポイントと、同業種に属する全企業について最も関連性が高いデータ特性を比較して算出されます。
モデルの推定値算出方法
本モデルでは、ターゲット企業のデータ特性と、特性が類似する企業群によるGHG排出量の分布との関係性を学習させています。分布の作成にはさまざまな機械学習法が適用されています。これにより、データに見られる複雑性や問題点にも対応できます。こうして、このモデルが学習した関係性を他の企業群にも適用できるようになります。
スコープ3モデル
現在、スコープ3の対象企業は石油・ガスおよび鉱業企業に限定していますが、今後新たな業界が追加されるにつれて対象企業数が増加することが見込まれます。
これらの企業のスコープ3モデルは、ボトムアップのモデルにトップダウンの機械学習モデルを組み合わせています。
ボトムアップ型モデルでは、企業の石油・ガス・天然ガス液、石炭、鉄鉱石の売上高および生産量などに加え、二酸化炭素排出量関連の各ファクター(生産単位ごとの二酸化炭素同等物排出量など)を用います。次に、そうした製品の使用や処理から生じる間接的排出量を算出します。トップダウン型機械学習モデルは、ボトムアップ型モデルで下から積み上げてきたデータの上部に位置するものです。算出されたスコープ3排出量、業種ごとの売上高、その他主要ファクターの関係性を学習することで二酸化炭素排出量を推定します。
石油・ガスおよび鉱業企業のスコープ3排出量に最も大きく寄与するのは、こうした企業が販売した製品の下流プロセスや利用であるため、石油・ガスおよび鉱業セクターについては売上高や生産高を使うことは効果的です。
本稿は英文で発行された記事を翻訳したものです。英語の原文と翻訳内容に相違がある場合には原文が優先します。